In case you’re tuning in late, the previous installment in this series is here. This is an absolutely ridiculously long blog post, feel free to either totally ignore it or to read only the top portion, it will likely contain all you need or want to know to keep up to date with what’s happening here. The rest is more of a detailed log of what I did to be able to get back into it quickly if I decide that ‘Ruby Is the One’.
A picture paints a thousand words I guess:
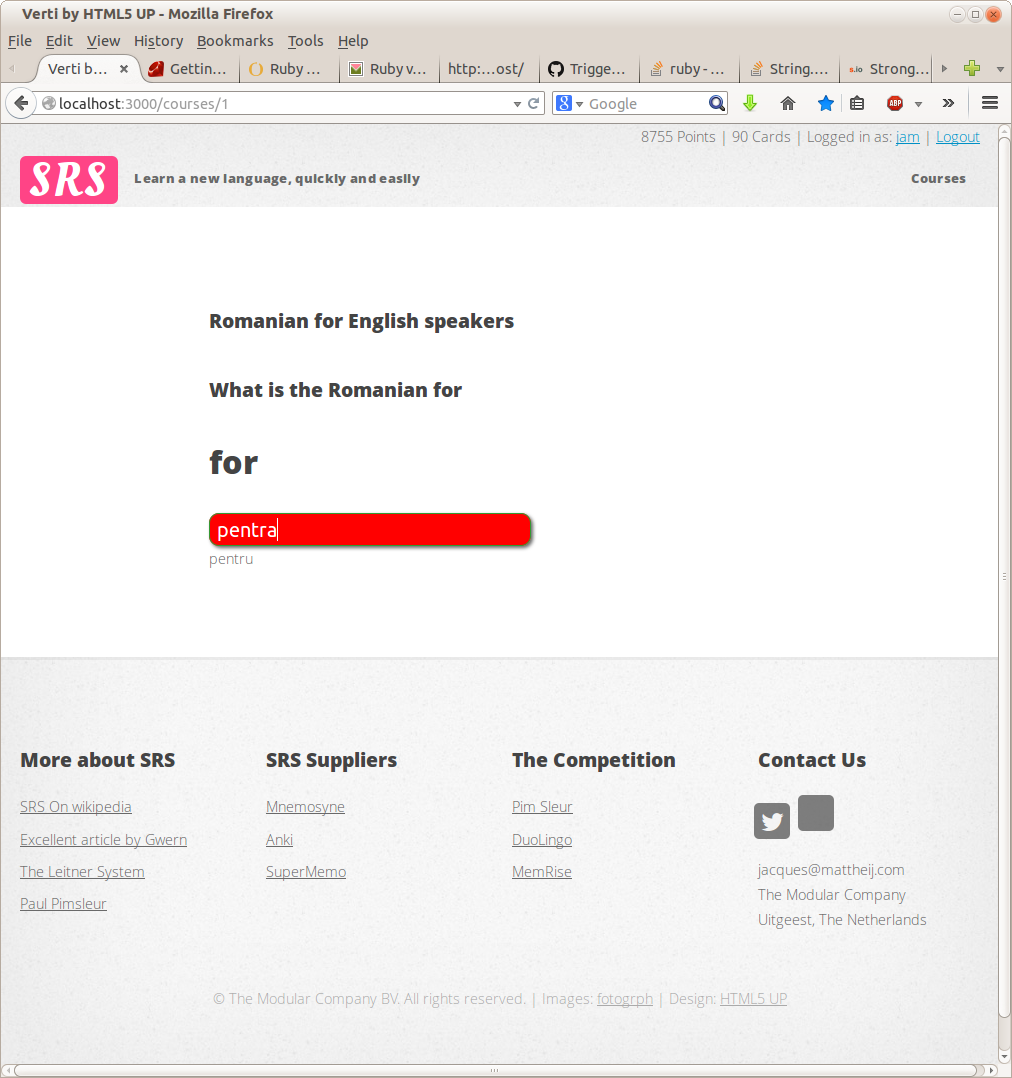
And yes, it works, you can actually learn Romanian with it, so I guess that’s ‘mission accomplished’ :) It’s also butt-ugly, works on mobile, tablets and so on (courtesy of the template, I did not do much work on that other than to resolve some conflicts).
The short version of what the last couple of weeks were like (resulting in that screenshot) is:
Install RubyOnRails
Dive headlong into rails
Run aground, decide to learn the Ruby language first
Learn Enough Ruby to make sense of rails
ported the PHP command line application to ruby
re-write all database interaction to use activerecord
move all the business logic into the data model
port the datamodel over to the demo rails application
drive to Amsterdam
re-install RoR on the machine here at the office
make a ‘user creation’ form
make a ‘login’ form
figure out how to log-in a user
install a template and chop it up
make the ‘available courses’ page
make the learning page
make the feedback from the server about the answer given work
make a top row that shows the user info + logout link
All in all it was more work than I thought it was and I ended up spending a frustrating amount of time just searching for stuff and being stuck on simple little details. The problem with rails is not the the information isn’t out there, the problem is that there is a ton of stuff out there that simply is no longer relevant but because everybody is playing the SEO game that data will forever pollute your ability to find out what is relevant and what is not. In the end it worked out though and I’m pretty happy with the result. This of course does not say anything yet about how it would be to deploy this particular solution, it only means I’ve managed to build a first version.
My first impression is that developing on RoR is (when you know what you’re doing, always helpful) fairly quick but the result is quite fragile, far more fragile than I expected. This is in part due to Ruby the language (which Rails can’t really do all that much about) which has some peculiar quirks and in part because of the way Rails is set up, it’s all ‘conventions’ and conventions translate into ‘things you should know and learn by heart’. This makes it a bit harder to get going. I’m used to reading a program much like I’d read a book, and that’s also how I normally write programs. In comparison, working with Ruby on Rails feels like someone tore the book up and scattered the pages in a hundred different places. Ruby is a funky little language that allows you to take all kinds of short-cuts, the Ruby code was on average about 25% smaller than the corresponding PHP code. And I don’t know Ruby and I know PHP like I know my back pocket so likely with some more knowledge I could save more code.
Another thing that strikes me is that Ruby is a language that almost asks for unintended side-effects to be present in your code. And that in turn is an excellent way to get security issues, if your ‘counterpart’ knows Rails (much) better than you do chances are that they’ll find something exploitable that you overlooked.
Even so, I’m fairly impressed with how concise the final solution is, how quick it got built In spite of all the hours of frustrating searching and the continuous feeling of going very slow and working ‘against’ the frame work only 16 days have passed since the last installment, when I didn’t know anything about Ruby yet, and 3 of those days were spent on the road driving from Bucharest to Amsterdam.
This code is so fresh and most likely contains tons of security holes and bugs that I’m not confident to put it out there, besides, this is only the evaluation of Ruby On Rails and the list of frameworks that remain is a long one.
The logfiles (you *really* should stop reading here)
Warning, this is an extremely long blog section detailing weeks of work to try to get up to speed with Ruby, then a couple more to work through Rails tutorials and then more still to get a minimally working version of the SRS application up and running. If you just want the ‘verdict’ you’ll have to wait until I have done this with all the platforms so I can compare them side-by-side, think of this as a progress report and a way to segment the various platforms into one-page-each. It is written the way it is so you get an idea of the work I did, in what order I did it and what I was thinking while I did it and what issues I encountered along the way and how I (hopefully) solved them. This is probably of limited use to you unless you are currently evaluating Ruby / Ruby On Rails.
I’m going to try to keep the external representation of the various implementations as close together as I can. So starting off with a ‘full fledged’ batteries included combo like RoR is a good way to find out what is missing in other offerings, and it will also get the first web based version of this working in (hopefully) short order. I don’t recall having ever written a line of Ruby before so consider me a total noob when it comes to this particular set.
While you’re reading this keep your eye on the ball and remember that I’m trying to learn some Romanian.
I start out where I imagine everybody else starting with Ruby On Rails starts out, the getting started guide and going step-by-step.
ruby -v ruby 1.9.3p484 (“2013-11-22”
sqlite3 –version 3.8.2 “2013-12-06”
gem install rails
After a long pause and a whole bunch of disk grinding and fan noises:
"ERROR: Error installing rails:
ERROR: Failed to build gem native extension.
/usr/bin/ruby1.9.1 extconf.rb
/usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:in require': cannot load such file -- mkmf (LoadError)
from /usr/lib/ruby/1.9.1/rubygems/custom_require.rb:36:inrequire’
from extconf.rb:1:in `
Some googling later it turns out that ruby-dev is also required:
apt-get install ruby-dev
Maybe someone should update that tutorial (and retry it periodically to see if it all still works as advertised). Little gotchas like this in the first few minutes can turn off newbies and will reduce adoption.
gem install rails
More disk grinding. It’s pretty hot here today and the gem installer uses a lot of CPU cycles according to the sounds coming from the machine. The machine I’m doing this all on is pretty ancient, all of 2G of ram and a regular drive. My ‘main’ machine sits back in the Netherlands under my desk there and would probably make short work of all this but I have this one to work with and I guess it is a lot better than chiseling 1’s and 0’s into stone tablets. After a good 15 minutes it is finally done. Rails is installed :)
rails -v Rails 4.1.1
Neat. So at least it looks like once you get past that ruby-dev hickup the rest works as advertised.
On with the tutorial!
rails new blog
After a couple of minutes this prompts for my root password, then after yet another couple of minutes tons of errors. Scrolling back I find that this is caused by not having sqlite3-dev installed (a header file is missing).
Easy to correct.
sudo apt-get install libsqlite3-dev
On error, retry:
rails new blog
This asks me if I want to overwrite a secrets file, I’ve yet to modify files here so I say ‘Y’.
A few minutes later the installation completes without further issues. At the end there is this line in the output:
“Warning: You’re using Rubygems 1.8.23 with Spring. Upgrade to at least Rubygems 2.1.0 and run gem pristine --all for better startup performance.”
Ok, sounds good. How do you upgrade Rubygems? More googling leads me to:
gem install rubygems-update
followed by:
update_rubygems
Which seems to install RubyGems 2.2.2
The tutorial next advises to start the embedded rails server from within the blog directory:
rails server
Only that doesn’t work…
/usr/local/lib/site_ruby/1.9.1/rubygems/dependency.rb:298:in to_specs': Could not find 'railties' (>= 0) among 0 total gem(s) (Gem::LoadError)
from /usr/local/lib/site_ruby/1.9.1/rubygems/dependency.rb:309:into_spec’
from /usr/local/lib/site_ruby/1.9.1/rubygems/core_ext/kernel_gem.rb:53:in gem'
from /usr/local/bin/rails:22:in
In a stackoverflow thread I found a hint that I should re-run ‘gem install rails’ as a regular user:
gem install rails
Rather than as root. So I tried that.
“You don’t have write permissions for the /usr/lib/ruby/gems/1.9.1 directory.”
This is a very bad idea:
chmod -R 777 /usr/lib/ruby/gems/*
So we won’t be doing that. Let’s try again as root:
sudo gem install rails
Try again:
cd blog rails server
/usr/lib/ruby/gems/1.9.1/gems/execjs-2.0.2/lib/execjs/runtimes.rb:51:in `autodetect’: Could not find a JavaScript runtime. See https://github.com/sstephenson/execjs for a list of available runtimes. (ExecJS::RuntimeUnavailable)
Hm. What does ruby or rails have to do with finding a javascript runtime?
More googling. In this stackoveflow thread I read that I have to enable a gem called ‘therubyracer’ in a file called ‘gemfile’. I load ‘gemfile’ into vi and indeed, there is a line like that. Remove the ‘#’ in front of the line (# marks are used as a comment indicator in ruby).
rails server
Could not find gem ‘therubyracer (>= 0) ruby’ in the gems available on this machine.
Run bundle install to install missing gems.
Ok.
bundle install
Tons of errors, the topmost of which suggests that I should install g++ first.
sudo apt-get install g++
bundle install
At this point we’re about 1.5 hours into the installation process. To save RAM I’ve killed firefox.
Lots of grinding and about 1⁄2 hour later:
“Your bundle is complete!”
rails server
=> Booting WEBrick
=> Rails 4.1.1 application starting in development on http://0.0.0.0:3000
=> Run rails server -h for more startup options
=> Notice: server is listening on all interfaces (0.0.0.0). Consider using 127.0.0.1 (–binding option)
=> Ctrl-C to shutdown server
[“2014-05-26”
[“2014-05-26”
[“2014-05-26”
Started GET “/” for 127.0.0.1 at “2014-05-26” Processing by Rails::WelcomeController#index as HTML Rendered /usr/lib/ruby/gems/1.9.1/gems/railties-4.1.1/lib/rails/templates/rails/welcome/index.html.erb (34.9ms) Completed 200 OK in 325ms (Views: 215.4ms | ActiveRecord: 0.0ms)
Yay! It appears we have a working RoR installation.
Excellent. It took a while but it looks like it is working.
The built in server is quite convenient when testing code on your local host.
Next the getting_started guide walks you through a bit of configuration and then you will be able to see your test page. After that you are prompted to create a ‘resource’, by making some changes to the config/routes.rb file.
The listed example shows that you should make it look like this:
Blog::Application.routes.draw do
resources :articles
root ‘welcome#index’ end
But that throws up all kinds of errors.
rake routes
rake aborted! NoMethodError: undefined method `application’ for Blog:Module
Changing ‘Blog’ back into ‘Rails’ seems to fix this for now (my understanding of the routing dsl is so minimal at this point that I have no clue what this all means, I will read the doc on the routing in a moment, maybe then I’ll have a better understanding).
Next we add a form and there is something weird about that, the tutorial tells you to change the first line of the form to:
<%= form_for :article, url: articles_path do |f| %>
But gives no explanation why the ‘url:’ has a trailing colon and the rest of the : characters in that form are at the beginning of the terms. It doesn’t explain much of anything anyway but this is a little strange.
The explanation underneath reads:
“The form needs to use a different URL in order to go somewhere else. This can be done quite simply with the :url option of form_for. Typically in Rails, the action that is used for new form submissions like this is called “create”, and so the form should be pointed to that action.”
Hopefully this will be explained in:
http://guides.rubyonrails.org/routing.html
So time to do some reading.
So what is it? url: or :url? According to the routing docs it is indeed url: so the tutorial got that bit wrong in the text but right in the example.
So the magic works, the predicted ‘Template is missing’ error shows up.
Next we add a bit of code to allow us to see what the controller receives.
There is this sentence in the tutorial at this point:
“The render method here is taking a very simple hash with a key of text and value of params[:article].inspect.”
Documenting
“render plain: params[:article].inspect”
And I really can’t make soup of this. What hash? What key of ‘text’?
I suppose the ‘key’ refers to the name of the field ‘text’, but that value then makes very little sense (after all, there are two fields, title and text), and that still does not explain the ‘hash’.
At the end of section 5.6 we’re told to insert the following bit of code to get around a ForbiddenAttributesError:
private def article_params params.require(:article).permit(:title, :text) end
But after I do this and refesh the page the error remains.
Says: you appear to be following a pre rails 4.0 tutorial with rails 4. You need to use strong params now.
But at the top the tutorial explicitly confirms that it should work with rails versions > 4.
I use the second line in the SO post answer:
# @comment = @post.comments.create!(params.require(:comment).permit(:comment_text,:link)
Convert its format to what I think should be required to make it work for articles:
# @article = Article.create(params.require(:article).permit(:title,:text))
Comment out the original line that made a new article:
# @article = Article.new(params[:article])
And commented out the bit that section 5.6 said I should have added:
#private
# def article_params
# params.require(:article).permit(:title, :text)
# end
And try again. Now rails complains about not having a ‘new’ action.
Checking above, I did not change ‘create’ to ‘new’. That’s an easy fix.
And now it indeed gives me:
“The action ‘show’ could not be found for ArticlesController”
Whoever maintains that tutorial certainly hasn’t been paying attention lately, and without stackoverflow and google to help I would have either thrown my computer out the window at this point or de-installed rails. Maybe this is some kind of secret plot by the RoR overlords to test newbies for the joint start-up required qualities of persistance and ingenuity? Or maybe they just don’t like newbies and want them to go away. I don’t know which it is but I can’t imagine this tutorial is leaving the people following it in good spirits.
Anyway, on we go.
I add the following line to config/routes.rb:
article GET /articles/:id(.:format) articles#show
And hit refresh:
/home/jam/svn/src/srs/www/ror/blog/config/routes.rb:4: syntax error, unexpected ':', expecting keyword_end article GET /articles/:id(.:format) articles#show
Most helpful. I change the line according to the format listed in an example lower down in the routes file to read:
get '/articles/:id(.:format)' => 'articles#show'
With ‘rake routes’ I verify that the route is indeed present:
Prefix Verb URI Pattern Controller#Action
GET /articles/:id(.:format) articles#show
articles GET /articles(.:format) articles#index
POST /articles(.:format) articles#create
new_article GET /articles/new(.:format) articles#new
edit_article GET /articles/:id/edit(.:format) articles#edit
article GET /articles/:id(.:format) articles#show
PATCH /articles/:id(.:format) articles#update
PUT /articles/:id(.:format) articles#update
DELETE /articles/:id(.:format) articles#destroy
root GET / welcome#index
I add the action and the view, hit refresh and indeed, the ‘article’ appears.
So far so good. One of the problems undoubtedly is that I’m a total noob to both ‘ruby’ and ‘rails’, but I suspect I’m not the only person that finds this tutorial as their first point of contact. And I just can’t get over how frustrating this whole experience is. It’s like being a failed Harry Potter, you’re being told to use all these spells that are supposed to have some magic effect, only they don’t and throw back errors at you all the time implicating you’re the one doing something wrong. And then after consult it always turns out that the spells you were given were wrong. Really annoying. Anyway, if I wasn’t the persistent type I would have never gotten into programming in the first place so I’ll try real hard to stop bitching about this but it’s getting to me. I sure hope the quality of ‘ruby’ and ‘rails’ is at a higher level than this tutorial.
The main issue I have at this point is that given the fact that Ruby does a ton of things under the hood that appear to be black magic to the user you should at least build up the students confidence that the magic actually works. Right now I feel as if a single ‘.’ or ‘,’ misplaced that does not have a relevant stack-overflow message waiting for me (assuming I know what to search for) will leave me totally stranded. You’re asked to do all these things without a proper explanation of what is going on, it’s a huge exercise in faith.
I suspect that one of the problems here is that I dove head-first into RoR without learning some Ruby first. So let’s divert for a bit and get a feel for ‘Ruby’ the language without looking at the framework.
https://www.ruby-lang.org/en/documentation/quickstart/
Some things to remember (when coming from some other language):
- Expressions work like they do in most other languages
- functions are defined using a ‘def’ … ‘end’ pair
- if a function has no parameters you can omit the () both during the declaration and the subsequent call
- even if a function has parameters, if the context is unambiguous then you can omit them
- Within a string #{varname} expands varname to the contents of varname.
- functions can be defined only once (so no erlang like tricks based on arity)
- you can call a method of an object by using object.method
- variable names are not prefixed by any special character
- irb (interactive ruby) will only attempt to process the code when it thinks it is complete (this can become quite messy with multi-line function definitions containing errors)
- you can use the respond_to? method to figure out what an object understands, this allows for code to reflect on what a class can do and adapt accordingly. For instance, you could try to see if you received a list or a simple variable by checking of the object you received understands “each”
- attr_accessor :someattribute will generate a getter and a setter method
- puts “Goodbye #{@names.join(”, “)}. Come back soon!” shows that you can do just about anything in between #{ }
Something weird happened during the tutorial: I defined a simple class according to what it said on the page there and then listed the instance methods:
irb(main):043:0> class Hey
irb(main):044:1> def initialize(name="World")
irb(main):045:2> @name=name
irb(main):046:2> end
irb(main):047:1> def say_hi
irb(main):048:2> puts "Hi #{@name}!"
irb(main):049:2> end
irb(main):050:1> def say_bye
irb(main):051:2> puts "Bye #{@name}, come back again!"
irb(main):052:2> end
irb(main):053:1> end
=> nil
Hey.instance_methods
=> [:say_hi, :say_bye, :h, :nil?, :===, :=~, :!~, :eql?, :hash, :<=>, :class, :singleton_class, :clone, :dup, :initialize_dup, :initialize_clone, :taint, :tainted?, :untaint, :untrust, :untrusted?, :trust, :freeze, :frozen?, :to_s, :inspect, :methods, :singleton_methods, :protected_methods, :private_methods, :public_methods, :instance_variables, :instance_variable_get, :instance_variable_set, :instance_variable_defined?, :instance_of?, :kind_of?, :is_a?, :tap, :send, :public_send, :respond_to?, :respond_to_missing?, :extend, :display, :method, :public_method, :define_singleton_method, :object_id, :to_enum, :enum_for, :==, :equal?, :!, :!=, :instance_eval, :instance_exec, :__send__, :__id__]
Spot the weird one? That ‘h’ in there is a definition I made before defining the class ‘Hey’, and yet it is a method in the class!
Let’s try that again, completely from scratch.
jam@homebox:~/svn/src/srs$ irb
irb(main):001:0> def h(name)
irb(main):002:1> puts "hello #{name}!"
irb(main):003:1>
irb(main):004:1* end
=> nil
irb(main):005:0> h("hey")
hello hey!
=> nil
irb(main):006:0> class Hey
irb(main):007:1> def initialize(name="World")
irb(main):008:2> @name=name
irb(main):009:2> end
irb(main):010:1> def say_hi
irb(main):011:2> puts "Hi #{@name}!"
irb(main):012:2> end
irb(main):013:1> def say_bye
irb(main):014:2> puts "Bye #{@name}, come back again!"
irb(main):015:2> end
irb(main):016:1> end
=> nil
irb(main):017:0> Hey.instance_methods
=> [:say_hi, :say_bye, :h, :nil?, :===, :=~, :!~, :eql?, :hash, :<=>, :class, :singleton_class, :clone, :dup, :initialize_dup, :initialize_clone, :taint, :tainted?, :untaint, :untrust, :untrusted?, :trust, :freeze, :frozen?, :to_s, :inspect, :methods, :singleton_methods, :protected_methods, :private_methods, :public_methods, :instance_variables, :instance_variable_get, :instance_variable_set, :instance_variable_defined?, :instance_of?, :kind_of?, :is_a?, :tap, :send, :public_send, :respond_to?, :respond_to_missing?, :extend, :display, :method, :public_method, :define_singleton_method, :object_id, :to_enum, :enum_for, :==, :equal?, :!, :!=, :instance_eval, :instance_exec, :__send__, :__id__]
irb(main):018:0> Hey.h "hello"
hello hello!
=> nil
irb(main):019:0>
Yup, that’s reproducible. So a class absorbs any methods defined separately just prior to that class?
Weird. I can also still call ‘h’ outside of the class:
irb(main):019:0> h("hello")
hello hello!
=> nil
irb(main):020:0> say_hi "jacques"
NoMethodError: undefined method `say_hi' for main:Object
from (irb):20
from /usr/bin/irb:12:in `<main>'
But the class methods are not accessible without an instance of the class. I don’t understand this, but I assume it is somehow intentional. Maybe someone more versed in Ruby can explain what is going on here.
Hey.instance_methods(false)
=> [:say_hi, :say_bye]
irb(main):022:0>
Shows only what we defined in the body of the class.
The cliff notes to ‘Why’s poignant guid on ruby’, about as short a crash course on Ruby as you’ll get:
- variables are all in lowercase
- strings can be made with both single and double quotes
- constants start with an upper case letter, so Constant is a constant
- :symbol is a symbol
- instance method invocation works like this: variable.method
- class method invocation works like this: Classname::method
- the normal argument passing looks like lots of other programming languages: variable.method(param1, param2)
- ‘kernel methods’ are core language functions such as ‘print’ they don’t require an object to be attached to, the default object Kernel:: is always searched if you type a method name.
- global variables have their name prefixed with a ‘$’
- instance local variables start with an @ sign, their scope is the local object
- class variables start with @@, their scope is the whole class
- code blocks are { between }, or between do and end, these are equivalent
- blocks can have 0 or more arguments between || characters just inside the block
- ranges look like this: (1..3) or (‘x’..‘z’)
- arrays look like this: [1, 2, 4]
- hashes http://www.ruby-doc.org/core-2.1.2/Hash.html – a ‘hash’ in ruby parlance is a dictionary that can only store definitions, they look like this: { “a” => “test”, “b” => “you know” } – you get the value stored at key ‘a’ back out of a hash like this: thehash[‘a’]
- regexps look like this: /regexp/
- Interesting: 5.==(6-1) returns ‘true’, so == is a method like every other
- << concatenates
- .reverse reverses a string
The guide lists “string”.each as a valid construct, but the interpreter complains when I try that. Apparently ‘each’ is no longer available, you now have to use ‘each_char’. I wonder why one would deprecate an existing behavior, breaking existing code and then to re-implement that behavior using a new name. It seems like a pointless exercise to me, nothing changes except that a bunch of people end up having to debug their code. And in an interpreted language such changes are extra nasty because you don’t get the benefit of a compile time check to see if your code is still at least correct at that level.
- string search/replace is called gsub, it is a method of the string class so you use it as string.gsub(“old”,“new”)
affixing ! to a method name does the operation ‘in place’ instead of returning a new result, it doesn’t seem to work for all operators though, a.+!(3) is not the equivalent of a+=3 (which works fine all by itself…), so the ! is part of the method name, not some kind of modifier that makes any method destructive
File::read(“filename.txt”) will return a string with the contents of the file
File::open(“filename.txt”,‘r’) do |f| block end executes the code in block with the filehandle of the open file in ‘f’
f << string where ‘f’ is a file descriptor will concatenate the string to the file contents (what about seek? does it write or only concatenates??)
very clever dir globbing example: Dir[’*.txt’].each do |file| system “cat ” << file end
there are multiple ways to do the same thing. t = [:a => ‘e’] + [:a => ’d’] is equivalent to t = [ {:a => ‘e’}, {:a => ’d’} ]
http://www.artima.com/intv/rubyP.html
“Yukihiro Matsumoto: Ruby inherited the Perl philosophy of having more than one way to do the same thing. I inherited that philosophy from Larry Wall, who is my hero actually. I want to make Ruby users free. I want to give them the freedom to choose. People are different. People choose different criteria. But if there is a better way among many alternatives, I want to encourage that way by making it comfortable. So that’s what I’ve tried to do. Maybe Python code is a bit more readable. Everyone can write the same style of Python code, so it can be easier to read, maybe. But the difference from one person to the next is so big, providing only one way is little help even if you’re using Python, I think. I’d rather provide many ways if it’s possible, but encourage or guide users to choose a better way if it’s possible. “
- t.sort_by { |e| e[:a] }.each do |t| print t end # sorts ’t’ by key ‘a’ for each element e by retrieving the value of e[:a]. That’s pretty concise!
- next functions like ‘continue’ in ‘C’
- break like it does in most other languages (it breaks out of the innermost loop)
- a switch statement looks like this in Ruby: case when value when value when value end (a bit strange how they chose to use confusing names for widely accepted constructs, it’s like exchanging ‘-’ and ‘+’ just because you can)
- return value of a function is the value of the last expression of that function
- (5..10) === 7 evaluates to ‘true’, because 7 is between the range start and end values
Slight detour through:
http://lambda-the-ultimate.org/node/934 http://www.tbray.org/ongoing/When/200x/2005/08/27/Ruby
Because of Ruby’s variable scoping rules.
Since the _why guide was written Ruby has evolved quite a bit, for instance, the block variable scope is now a lot more sane, the example on page 48 (fortunately!) no longer works as advertised. Variables declared outside of a block are no longer affected by what goes on inside of a block. See here:
http://ruby.about.com/od/newinruby191/a/blockvariscope.htm
- classes are defined like this: class ClassName bodyoftheclass end
- 5.next gives you the next number after 5
- (5.5).floor.next first truncates the float to an int, then calls next
- object.class returns the class for that object
- b = a.class.new -> make another object ‘b’ of the same class as object ‘a’
- you can reach the current object from within a class definition by using ‘self’
- you can add new methods to existing classes, including kernel classes! (bad idea ™)
For instance, this is how you can add a ‘square’ method to numbers
irb(main):152:0> class Fixnum
irb(main):153:1> def square
irb(main):154:2> self * self
irb(main):155:2> end
irb(main):156:1> end
- respond_to?(“methodname”) applied to any class tells you if that class has a method ‘methodname’ (or should I say ‘knows how to respond to a message ‘messagename’)?
- you can slice strings like this: “abcde”[3..4]
- you can split strings on delimiters using “ab-cd-ef”.split(“-”)
- new class creation: class ClassName < parentclass; end (why does it need that ‘;’ there?)
- you can query the parent class with the superclass method: ClassName.superclass
- modules govern namespaces
- to define a class with all the entities in a module you use ‘extends’ as in ‘class X extends ModuleName; end’
- a *argument to a function will be passed in as an array
- attr_reader will create getters for the symbols passed as arguments, for instance attr_reader :test :test1 will create reader functions for variables with that same name
- attr_accessor does both readers and writers, attr_writer of course only writers
- class << ClassName is used to add class methods (methods that can be called on the class rather than on an instance of the class)
- a mixin is a module ‘included’ into a class, it instantly endows the class with all the stuff in the module
reading and processing the contents of a web page: require ‘open-uri’
Searching all found items containing the word `truck’.
open( “http://preeventualist.org/lost/searchfound?q=truck" ) do |truck| puts truck.read end
similar, but line-by-line processing: require ‘open-uri’ open( “http://preeventualist.org/lost/searchfound?q=truck" ) do |truck| truck.each_line do |line| puts line if line[‘pickup’] end end
I don’t particularly like the ‘if x’ conditional appended to that line, it feels a bit backwards to me. Imagine the instructions for disarming a bomb read ‘cut the red-green wire if the blue wire is still connected’. boom. Too bad, you should have parsed the instructions first before you started to execute them!
yielding is a way to let two blocks of code communicate, the ‘inner’ block passes information to the ‘outer’ block with every time yield is executed. Or should I say ‘inner blocks pull data from outer blocks whenever they need to’? It’s reminiscent of co-routines (which ruby also has: http://rubydoc.info/stdlib/core/1.9.2/Fiber), one routine the producer, the other the consumer.
‘brief’ style versus verbose style (both are identical in function):
open( “idea.txt” ) { |f| f.read }
open( “idea.txt” ) do |f| f.read end
traits in a parent class allow for elegant subclassing without having to pass in tons of (unnamed) parameters in the initializer use them like this in the parent class ‘traits :traita, :traitb, :traitc’
@x ||= {} is a little trick to ensure that a variable exists before it is used. The ||= says ‘if this varible does not exist yet then make a new one of this type, but if it does exist then adding an empty list to it won’t change anything’. I’m not sure why that works, you’d say that the ||= should fail if x does not exist yet, because it’s syntactically equivalent to x = x || {}
I got a little lost around page 109, the metaprogramming bit. It looks like one program is writing another, and not only is it able to evaluate code that wasn’t present in the original program, it can be used to construct entirely new objects / classes and so on. This is powerful but also asking for trouble because it can become very hard to reason about such programs. It’s akin to macro expansion, but more powerful.
you can overload just about everything too, including the basic operators
This probably makes ruby absolutely great at writing DSLs but it will be a nightmare to debug because you’ll never know what you are looking at means without backtracking very precisely through how you got where you are. Imagine looking at some program and seeing ‘a = b * c’. In most languages it would be fairly obvious what this does, the product of b and c is stored in variable a. Maybe b and c are arrays or matrices but at a minimum you’d expect some kind of multiplication to be going on there. In Ruby this is not the case. ‘a = b * c’ could mean literally anything, the only thing you can distill from that bit of code is that b and c are somehow combined using the operator ‘*’ and that the result of that combination is stored in a. Context decides whether this is two variables being multiplied or two battle ships exchanging fire or two images being compared. For a lark, someone could have decided to turn * into the division operator… Powerful, but also very dangerous, hard to debug and easy to have unintended side effects.
I should re-read the portion on meta programming when I understand Ruby a bit better.
- string formatting in Ruby: “abc %s and %d” % [“jaja”, 3]
- inside double quotes #{ } allows you to escape to run ruby code (security concerns here, this goes way beyond variable substitution?)
- reminder: globals start with a $
- you can generate exceptions using ‘raise ErrorNo, “Description”
- you can recover from errors by using the rescue label
- you can create an array of strings quickly by using %w{a list of words} this gets transformed into [‘a’, ‘list’, ‘of’, ‘words’]
- %x{} -> execute in a shell, %Q{} -> acts like a regular double quoted string
- if ‘a’ is a list and you do ‘a = b’ then b contains a reference to a, not a copy of the list so modifying b modifies a and vice-versa
- you can make an actual copy by using the .clone method, and then there is ‘.dup’ to create copies of objects that have been locked http://ruby.about.com/od/advancedruby/a/deepcopy.htm
- you append a value to an array using the << operator (contrary to what the stackoverflow article on the same question says!), so a << 5 appends the value 5 to a pre-existing array a.
If you run irb with
irb –readline -r irb/completion
You can type the name of an object, append a ‘.’ and then hit Tab, this will show you all the methods you could call.
For some reason the default ruby install does not come with the embedded documentation (ri).
Ok, that’s the end of the ‘Poignant Guide’, thanks Jonathan. (some joker now has _why’s domain so I won’t be linking there from here).
Porting the command line app
The PHP command line application is as good a place as any to start working with ruby. It’s not overly large and has all the business logic in it and needs to work with the database. Let’s port it to ruby to see what that feels like.
First we need to install the mysql client development libraries:
sudo apt-get install libmysqlclient-dev
Next, we need the mysql gem:
gem install mysql
Now ruby scripts should be able to access mysql databases.
A quickie check in irb if that’s true:
irb(main):001:0> require "mysql"
=> true
irb(main):002:0> con = Mysql.new('localhost', '', '', 'srs')
=> #<Mysql:0x8a48f14>
irb(main):003:0> rs = con.query('select * from users')
=> #<Mysql::Result:0x8a190c0>
irb(main):004:0> rs.each_hash { |h| puts h['nick']}
system
jam
=> #<Mysql::Result:0x8a190c0>
irb(main):005:0> con.close
=> #<Mysql:0x8a48f14>
Looks like it works :)
About 20 minutes into porting the console application I hit a bit of a roadblock. The standard mysql library module does not allow you to fetch a result from a prepared statement. This results in terribly ugly code which causes a one-liner to become something that spans a couple of lines. In the PHP world I use my own wrapper library for stuff like this, but for ruby I decide to see what’s available out there (this also gives a bit of an idea about how the ruby eco system works wrt to contributed software). I find this: http://sequel.jeremyevans.net/
gem install sequel
installs it, and we’re off again. I’ll change the bits of code written up to that point to use the sequel gem, it looks pretty easy to use. I could use ‘activerecord’ as well I guess but why not give this lightweight module a shot and see how far it takes me.
hash = $dbcon.fetch(“select * from users where nick=‘%s’” % nick).all[0][:pwhash]
that looks manageable. Still has an ugly * and .all[0] in there that’s technically not needed but that’s fixable:
$dbcon = Sequel.mysql("srs")
# fetches the first record of a set
def $dbcon.single (q)
self.fetch(q).all[0]
end
# fetches the first value returned by a query
def $dbcon.simple (q)
self.single(q).first[1]
end
This is a little snippet from the db initialization code. To ‘fix’ the Sequel class we add two new methods to the class, one that will simply return the first result from a set, another to return the first field from the first result from a set. This allows you to do:
hash = $dbcon.simple("select pwhash from users where nick='%s'" % nick)
That looks better. Of course modifying code from the outside like this is a bit (ok, a lot) hackish but I want to get a feeling for what Ruby can do and even if this is probably not idiomatic ruby the fact that you can extend libraries so easily is a powerful concept (and probably a very dangerous one, imagine if the vendor of ‘Sequel’ decides to add a ‘single’ or a ‘simple’ method to the base class with different meaning! So for anything but this ‘toy’ program this is probably a very bad idea.
Next up, the hash comparison. The passwords in the system are hashed using ‘bcrypt’, with a workfactor of ‘10’ and the blowfish algorithm. This results in hashes with the prefix $2y$10$ followed by the salt and the hash. Testing these passwords with the default Ruby ‘BCrypt’ library results in a non-match, even with the correct password. It turns out that the maintainer of the BCrypt gem made a decision to add ‘2x’ instead of ‘2y’ and that any ‘2y’ passwords will not match, even if the lib is perfectly capable of doing the verification.
The solution? Replace the ‘y’ with an ‘a’ and then the comparison will succeed for correct hashes. See: http://stackoverflow.com/questions/20980859/using-bcrypt-ruby-to-validate-hashed-passwords-using-version-2y and https://github.com/codahale/bcrypt-ruby/pull/91 lists an open pull request with a fix.
This little gotcha cost me about 2 hours to figure out, but for now the ‘replace-the-y-with-an-a’ workaround seems to do the trick.
Ruby does not have a ++ operator!! So no increments of integer variables without doing something like += 1.
No big deal, but I’m sort of used to this and it would come in handy when porting code. But using iterators most of the increments should disappear. Still, it wouldn’t cost anything to include this operator in ruby and it’s surprising that such a simple thing is missing.
Interesting: Porting the php code to ruby turned up a bit that I should have extracted into a function (the loop where the choice was made which course to study). The reason why I found that this should have been a function was that there simply was no elegant way to do it ‘in place’, but then once the function was made it looked a lot better!
Ruby’s inconsistent use of {} for blocks is driving me crazy. I never know when they are permitted, expected or obligatory!
loop {
}
Is fine but
if a {
}
Is not… Just check this out:
puts [1,2,3].map{ |k| k+1 }
2
3
4
=> nil
puts [1,2,3].map do |k| k+1; end
#<Enumerator:0x0000010a06d140>
=> nil
What is happening here is that the {} have different precedence than do .. end. Very confusing, even after multiple tries I can’t find a way to convert the curly braces example to a do .. end example.
Maybe something like this:
irb(main):029:0> [1,2,3].map do |k| puts k+1; k+1 end
2
3
4
=> [2, 3, 4]
irb(main):030:0> [1,2,3].map { |k| puts k+1; k+1 }
At least now they both behave identical.
A nice little ‘gem’, wirble, it adds syntax highlighting and auto completion:
sudo gem install wirble
see http://tuxdna.wordpress.com/2011/11/13/autocomplete-and-colorize-your-ruby-shell-irb-with-wirble/
From here on forward porting the command line version of the ‘learn’ script to ruby went fairly straightforward, a couple of minor glitches and a few functions that I had to find a work-around for but nothing that I would not have experienced going the other way (from Ruby to PHP).
I note that the lines on average are a bit shorter than in PHP, they look cleaner but there are definitely more of them, in part this is because Ruby is so terse at times that you feel the need to explain what’s going on. Code + comments = a constant…
Part of this lies in that PHP basically contains anything you would like to use as soon as you start the interpreter in terms of crypto, database, string transliteration, json and so on. With ruby you have to include that explicitly.
Of course there is a very good chance that I simply do not really know what I’m doing in Ruby just yet. Another thing I noticed is that because not everything is in the ‘base package’ you have to resolve external dependencies all the time, there is always ‘one more gem’ to install and it could be quite easy to either forget such a gem or to find that when you build up a machine that your ‘favorite gem’ is no longer being supported. For this reason I’ve always tried to rely as little as possible on external dependencies but this is the ‘ruby way’ I guess. PHP has this too (pecl) and I’ve stayed away from that for much the same reasons. But in PHP land you can get away with that, in Ruby land you need to include those external dependencies just to get basic stuff.
All in all porting the learn.php program took less than a day, I learned a bit more about how ruby works under the hood and I have a better grasp of the syntax. When I’m more proficient at Ruby I should probably re-visit this to see if I can do a better job of it, which hopefully will make the program more compact and/or easier to read.
Here are the cloc stats of both the ruby and the php version:
$ cloc learn.rb
http://cloc.sourceforge.net v 1.60 T=0.03 s (30.1 files/s, 12351.2 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Ruby 1 123 92 196
PHP 1 105 57 193
-------------------------------------------------------------------------------
That’s very close. In fact, if you discount the functions that were added for compatibility with php then ruby comes out slighly ahead.
To gain some more experience, I got rid of the sequel gem and re-did the whole thing using active record. This also lines me up a bit better for using Rails.
Extremely frustrating moment. Examples all over the place on how to use ActiveRecord with ruby. If I use one of these examples (the most trivial), for instance:
Most of those examples/documentation give absolutely no indication what version of activerecord / ruby / possibly rails they are for.
So this works:
>> u = User.where(:nick => 'jam').first
=> #<User id: 2, nick: "jam", pwhash: "$2y$10$Hpp9rAx9d/eWIFi.E.f7pu1YDV4qfzfAwGvMpBzF6wb...", score: 6055, email: "jacques@mattheij.com", newcardsperday: 20, cardspersession: 25, decay: 3, language: "en", initialinterval: 5>
And this does not:
>> u = User.find(:first)
ActiveRecord::RecordNotFound: Couldn't find User with 'id'=first
Even though that example is used in just about every tutorial out there.
Finally I found this guide which appears to be up-to-date and relevant:
http://guides.rubyonrails.org/active_record_querying.html
Usercourse.joins(:user).where(user_id: 2)
Tbh, after fiddling around with activerecord for a day or so now I’m really wondering how ORMs improve over SQL, but that’s probably just the novelty and the frustration talking. For instance, if I have a database with users collection scores I could do this: “update users set score=score+10 where id=1” without having to worry about locking records or anything like that. A user logged in more than once on the system could hit the server multiple times and it would all work like clockwork. But using an ORM that o-so-simple problem suddenly gets a lot harder. Just using user.score += score; user.save is not going to cut it! After all, who is to say that in another thread the exact same thing isn’t happening, causing one of the updates to be lost! Anyway, that’s a contrived example but you can see that ORMs are not a silver bullet by any means. What they do though is make your code more compact, hopefully easier to read.
The activerecord version of the console application in Ruby clocks in at 164 lines of code, but a good part of that is the elimination the ‘grade_answer’ function and inlining it. The reason why that was feasible is that the active record code was so much more readable compared to hitting the database directly using SQL statements that the duplication of the branches in the grade_answer function and the switch statement jumped out at me. So I merged the two and eliminated the function, resulting in a slightly longer version of the process_answer function but all in all still a good chunk of code elided and a cleaner overall flow. Not that that matters in a toy project like this but in a larger project such savings can add up.
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Ruby 1 100 86 161
-------------------------------------------------------------------------------
I should probably work a bit more on this code to move all the business logic to the model rather than to have it spread out all over the program. Especially the fetching of the next card to learn, grading and rescheduling are all bits that should live in the model.
Ok, back to our scheduled program of learning Romanian… Further reading to be done:
http://guides.rubyonrails.org/active_record_basics.html
I like the concept of migrations, but for now I’ll stick with doing schema maintenance through ALTER and CREATE TABLE statements in mysql, I don’t like the idea of getting so tied into any one eco system that the price of switching becomes too high, it would make evaluating other language/framework combo’s harder skewing the choice towards ruby/rails before all the data is in.
For some reason active record never detected the relationship between the various tables that are present in the schema. Not sure what is going on there, it’s easy enough to fix using some magic in the model but this should have been handled automatically, otherwise what’s the point of defining the relationships in the schema to begin with? I also suspect that under the hood there is a lot more chatter between AR and the database going on than I’m currently aware of but since this is a prototype any kind of attention spent on that would be a serious case of premature optimization so we’ll let all of that rest for now.
Another thing that worries me is the start-up time of the ActiveRecord module. Initializing the model takes well over 1 second on this machine(!) and I’m the only person using it. Ok, it’s a slow box, but still, that seems ridiculously slow to me.
So, after a gigantic detour this is the page where we left off:
http://guides.rubyonrails.org/routing.html
In section 1.2 I now finally understand what they meant with this snippet:
<%= link_to 'Patient Record', patient_path(@patient) %>
All it does is reverse the route, given a patient it creates the link to that specific patient.
notes for the routing guide:
- ‘resources :photos’ generates a whole pile of default routes for standard crud operations on ‘photos’
- “get ‘profile’, to: ‘users#show’” simple routes look like this
- singular resources still map to plural controllers, so ‘resource :customer’ will map to the customers controller
- you can nest controllers inside namespaces like this: namespace :xxx do resources: objects end, this makes /xxx/resources/ etc
This is extremely compact, but there is some risk here as well, you could be creating more routes than you’re aware of and with default controller actions that might cause trouble. Do controllers exhibit default actions?
Here is the spec for all the actions that we want our web application to perform:
- *the usual account creation
- *login
- logout
- *generating a list of available courses
- *a single page with a larger description of the courses
*a way to start learning a course
*a page where the actual learning takes place
*a place where the answer to a question gets posted
a page where you can track your progress
a page where you can view your profile details, courses selected etc
a page where you can add cards
Only the actions marked with a ‘*’ are required for the evaluation.
Since it all starts with the routes, let’s lay those out first:
resources :users, :courses
post '/users/login', to: 'users#login'
get '/learn/:filter', to: 'usercards#learn'
post '/learn/:usercardid' to: 'usercard#answer'
Ok, back in NL 2275 km of driving later…
Re-play the installation of Ruby and Rails on my machine here:
apt-get install ruby
Ah no, that installs 1.8
apt-get remove ruby apt-get install ruby1.9.3
(why don’t they make that the default?)
apt-get install sqlite3 apt-get install libsqlite3-dev gem install rubygems-update update_rubygems apt-get install g++ gem install execjs apt-get install libmysqlclient-dev gem install mysql
gem install therubyracer
for some reason therubyracer did not work for me this time around but installing nodejs seems to have done the trick. Weird dependency!
apt-get install nodejs
gem install rails gem install bcrypt
mkdir ~/test cd ~/test
rails new blog
rails server
=> Booting WEBrick
So even though that’s the second time I’m doing this it still required some fixes to the process. I’ll need to test this on a VM to make sure I really have all the requirements down now.
Fragile! Anyway, it works (again). On to more productive matters.
(verified that ruby learn.rb works again as well).
In preparation to making this into a rails website, I’m first going to move all the business logic into the model. Hopefully that will survive a transition into a web app intact.
How do you ensure that for a given ruby / ruby on rails application all the relevant gems have been installed?
Ah, that’s what ‘bundle install’ is for.
added the bootstrap gem
gem install twitter-bootstrap-rails
Update the gemfile, then run bundle install again
I installed a template from one of those template sites (http://html5up.net/verti).
Installing a template is a bit messy, you have to rip it apart and place the various pieces where rails expects them, and even then it can be quite a chore to work out why things are not doing what they’re supposed to. Rails has an ‘asset pipeline’, a piece of magic that tries to compile all your css and whatnot for speed but frankly it is more trouble than it is worth. In the end I stuffed all the css files in /css/ and did a bunch of @imports to include them in the layout. Not as nice and probably not as fast but for now it works, I can re-visit this later if I want to continue with rails.
So, now we have ‘basic navigation’ and we can add the links to the template. I need to figure out how to log in a user / log a user back out again.
What’s a real pain is that every time I find a tutorial or some piece of information on how to achieve ‘x’ in rails it is invariably out-dated, deprecated, no longer maintained or just plain wrong. For instance, a tutorial on how to create a user signup process in Rails contained a whole bunch of errors, bad advice (which could lead to security issues) and deprecated stuff. Fixing that took a long time.
You’d never guess it but that ‘comment’ at the end of the line is not a comment. This had me stumped for a long time.
validates :password, :password_confirmation => true #password_confirmation attr
So, Ruby -> Rails -> JavaScript (Unavoidable) -> Coffeescript? Wtf. So I have to learn yet another language to be able to use rails. This sucks. By the way, the information on how to do stuff is literally all over the place. Railscasts (what? I have to watch a video in order to do something with a framework? I really would simply like to see a solid example that does not involve me hunting across 12 different websites to pull all the pieces together, let alone some video that was likely out-dated on the day that it was made. Forgive me for being grumpy but if frameworks are supposed to make you more productive then I’m currently not experiencing that feeling).
Finally, after many hours of messing around and reading the answers to this stack overflow question solved it:
http://stackoverflow.com/questions/13242315/rails-remote-forms-validation
I still can’t really believe that that is the real solution but at least it seems to work. You’d think there would be a much more generic way of handling the response rather than to write a bunch of jquery to pull the validation errors out of the json response.
But ok, it works so let’s not complain. Well, it works if you have javascript enabled. I really dislike the way the webs is developing in this sense, javascript should not be a requirement per-se and the amount of cruft that gets added to a webpage in order to achieve something that could have just as easily been achieved by expanding the HTML standard (for instance, by adding a ‘validate’ attribute to fields with a regexp of permitted values, or even a ‘validate_src=‘url” for an online validator in case you need to do backend stuff to determine if the contents of a field are valid. Anything but JavaScript!).
Another thing that would really help here is a reference application that you can simply download that shows you ‘how it’s done’ using rails version ‘x’ rather than that every developer has to replicate the effort to piece it all together. Maybe I should post the SRS app sources so people can refer to them.
Useful reading:
http://www.railstutorial.org/book/filling_in_the_layout
Little by little I cribbed together the knowledge of how things are done the ‘ruby on rails’ way, it’s incredible how fragmented the information is.