tldr: limit your GPUs to about 2/3rd of maximum power draw for the least Joules consumed per token generated without speed penalty.
–
Why run an LLM yourself in the first place?
The llama.cpp software suite is a very impressive piece of work. It is a key element in some of the stuff that I’m playing around with on my home systems, which for good reasons I will never be able to use in conjunction with a paid offering from an online provider. It’s interesting how the typical use-case for LLMs is best served by the larger providers and the smaller models are just useful to gain an understanding and to whet your appetite. But for some applications the legalities preclude any such sharing and then you’re up the creek without a paddle. The question then is: is ‘some AI’ better than no AI at all and if it is what does it cost?
What to optimize for?
And this is where things get complicated very quickly. There are so many parameters that you could use to measure your systems’ performance that it can be quite difficult to determine if a change you made was an improvement or rather the opposite. After playing around with this stuff a colleague suggested I look into the power consumption per token generated.
And that turned out - all other things being equal - to be an excellent measure to optimize for. It has a number of very useful properties: it’s a scalar, so it is easy to see whether you’re improving or not, it’s very well defined: Joules / token generated is all there is to it and given a uniform way of measuring the property of a system you can compare it to other systems even if they’re not in the same locality. You can average it over a longer period of time to get you reasonably accurate readings even if in the short term there is some fluctuation.
You could optimize for speed instead but for very long running jobs (mine tend to run for weeks or months) speed is overrated as a metric, but for interactive work it is clearly the best thing to optimize for as long as the hardware stays healthy. And ultimately Joules burned per token is an excellent proxy for cost (assuming you pay for your energy).
Creating the samples
So much for the theory. In practice though, measuring this number turned out to be more of a hassle than I thought it would be. There are a couple of things that complicate this: PCs do not normally come with easy ways to measure how much power they consume and LLama doesn’t have a way to track GPU power consumption during its computations. But there are some ways around this.
I started out by parsing the last 10 lines of the main.log file for every run of llama.cpp. That works as long as you only have one GPU and run only one instance. But if you have the VRAM and possibly multiple GPUs this will rapidly become a hot mess. The solution is to ensure that every run pipes its output to a unique log file, parse the last couple of lines to fish out the relevant numbers and then to wipe the log file.
Sampling the power consumption was done using a ‘Shelly’ IP enabled socket, it contains a small webserver that you can query to see how much power is drawn though the socket. It’s not super precise, secure or accurate but more than good enough for this purpose. Simply hit
http://$LANIPADDRESS/meter/0
and it will report the status of the device as a json object, which is trivial to parse. Nvidia’s nvidia-smi program will show you the status of the GPUs and report their current power draw. Subtract that out and you’re left with just the CPU, RAM, MB and the drives.
Experiment
You then let this run for a while to give you enough samples to draw conclusions from. In order to figure out what the sweet spot of the setup I have here is (right now 2x 3090, i7) I stepped through the power consumption of the GPUs in small increments. 25 Watts per step, with a multi-hour run to get some precision in the measurements. Nvidia cards have an internal power limiter that allows you to set an upper limit to their consumption in Watts for a dual GPU setup the command line is:
nvidia-smi –power-limit=$Wattage –id=0,1
Just replace $Wattage with whatever limit you desire, but keep it above 100 and below the maximum power draw of the GPU for meaningful results.
Doing this for a series of steps using the Llama 13B 5 bit sampled model (which uses about 10G of VRAM), running four instances of llama.cpp concurrently (so two on each card) for an hour per step to reduce sampling inaccuracy gives the following graph of power consumption limits of the GPUs (horizontal) vs Joules consumed per token generated (vertical):
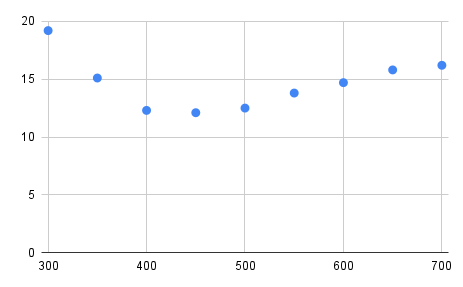
In tabular form:
GPUs (W) tps J/token GPU Temp (W)
300 27 19.2 43
350 35 15.1 48
400 48 12.3 50
450 52 12.1 53
500 51 12.5 53
550 49 13.8 55
600 50 14.7 57
650 50 15.8 60
700 50 16.2 63
Conclusion
The ‘sweet spot’ is pretty clear, the graph starts off on the left at about 19 Joules per token because the simple fact that the machine is on dominates the calculation. Not unlike a car that is idling or going very slow: you make no progress but you consume quite a bit of power. Then, as you ramp up the power consumption resulting in more processing efficiency increases fairly rapidly, up to a point. And after that point efficiency drops again, this is because now thermal effects are dominating and more input power does not result in that much more computation. If you live in a cold climate you may think of this as co-generation ;) In an extreme case you might run into thermal throttling, which is because of the way llama.cpp handles the interaction between the CPU and GPU just going to lead to a lot of wasted power. So there is a clearly defined optimum, for this dual 3090 + i7 CPU that seems to lie somewhere around 225W per GPU.
The efficiency is still quite bad (big operators report 4-5 Joules / token on far larger models than these), but it is much better than what you’d get out of a naively configured system, resulting in more results for a given expense in power (and where I live that translates into real money). If you have other dominant factors (such as time) or if power is very cheap where you live then your ‘sweet spot’ may well be somewhere else. But for me this method helped run some pretty big jobs at an affordable budget, and it just so happens that the optimum efficiency also coincides with very close to peak performance in terms of tokens generated per unit time.
Caveats
Note that these findings are probably very much dependent on:
- workload
- model used
- the current version of llama.cpp (which is improving all the time) and the particular settings that I compiled it with (make LLAMA_FAST=1 LLAMA_CUBLAS=1 NVCCFLAGS=“–forward-unknown-to-host-compiler -arch=sm_86” CUDA_DOCKER_ARCH=“sm_86”)
- Hardware
- GPU (Asus ‘Turbo’ NV 3090)
- CPU (i7-10700K stepping 5)
- avoid thermal throttling (which would upset the benchmark)
- CPU and case fans set to maximum (noisy!)
- GPU fans set to 80%
- ambient temperature (approximately 24 degrees in the room where these tests were done)
- Quite possibly other factors that I haven’t thought of.
Please take these caveats seriously and run your own tests, and in general don’t trust fresh benchmarks of anything that hasn’t been reproduced by others (Including this one!) or that you yourself haven’t reproduced yet. If you have interesting results that contradict or confirm these then of course I’d love to hear about it via jacques@modularcompany.com, and if the information warrants it I’ll be more than happy to amend this article.